> For the complete documentation index, see [llms.txt](https://docs.langstack.com/welcome/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.langstack.com/welcome/in-depth-learning/connectors/onedrive-connector/usage-of-onedrive-connector-in-etl-pipeline/onedrive-connector-as-a-destination.md).
# OneDrive connector as a destination
The ETL pipeline, to transfer customer data from a Langstack entity to a csv file on OneDrive, is created as follows.
{% hint style="info" %}
To see step-by-step instructions of how to create an ETL pipeline, [click here](/welcome/get-started/learn-langstack/introduction-to-etl-pipeline.md).
{% endhint %}
* An ETL pipeline named “TestEntitytoOneDrive” is created.
* To connect to the data source, the necessary information is added in the Data source section:
* The “Entity” tab is selected.
* The entity “CustomersData” is selected from the drop-down menu.
* To connect to the data destination, the necessary information is added in the Data destination section:
* The “Connector” tab is selected.
* For this example, “OneDrive123” is selected from the drop-down menu. The connector can be added by selecting a connector from the drop-down menu or a new connector can be created by clicking the \[+] button.
* To go to the settings, click the “Edit the settings” arrow.
* To disallow multiple simultaneous runs of the ETL pipeline, the toggle button is left enabled for “skip execution while in progress”. Enabling this toggle button defines that the execution of this ETL pipeline will be skipped when there is one already in progress.
* The default selection for ETL pipeline execution is “Immediate”.
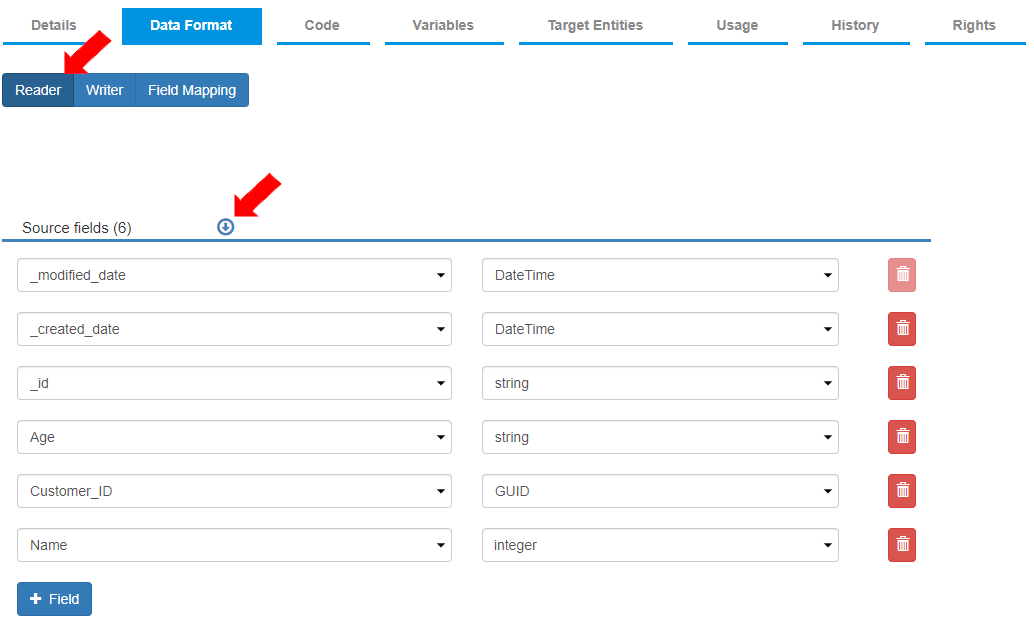
* To align the source fields with destination fields, the settings for the reader and writer format are defined in the “Data Format” tab. The “Reader” tab is selected by default. For this example, the fields are added as per the image below.
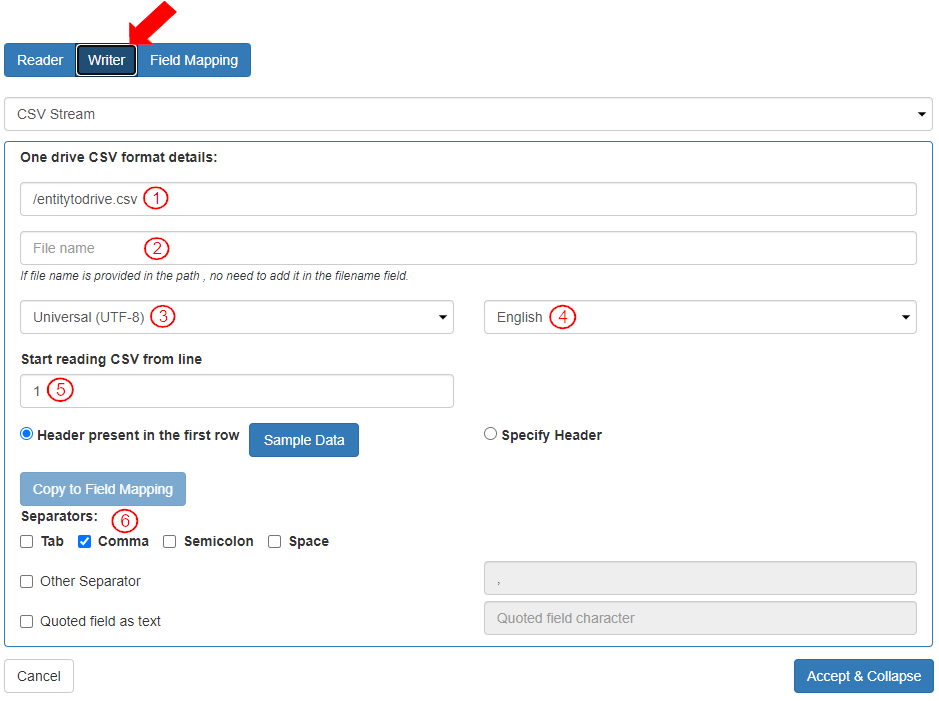
* To update the settings for how the data should be written, select the “Writer” tab.
* The writer stream is “CSV Stream.”
* To add the table name, click on the “Edit the settings” arrow.
* To add details necessary to write the records, the settings in this section “OneDrive CSV format details:” are defined as follows:
1. In the field “File path or File URL or Folder path or Folder URL” the file path is entered.
2. The “File name” is left blank as it is included in the File path.
3. The “CharacterSet” is selected as “Unicode(UTF-8)”.
4. The “Language” is selected as “English”.
5. The “Start reading CSV from line” is defined as “1”.
6. The “separator” is selected as “Comma”.
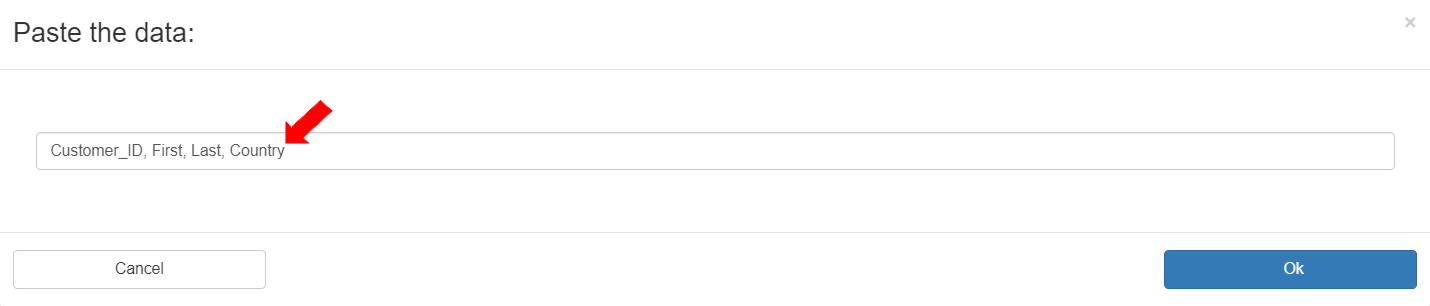
* In the “Sample data”, the column names of the source file are pasted: “Customer\_ID,Name,Age”.
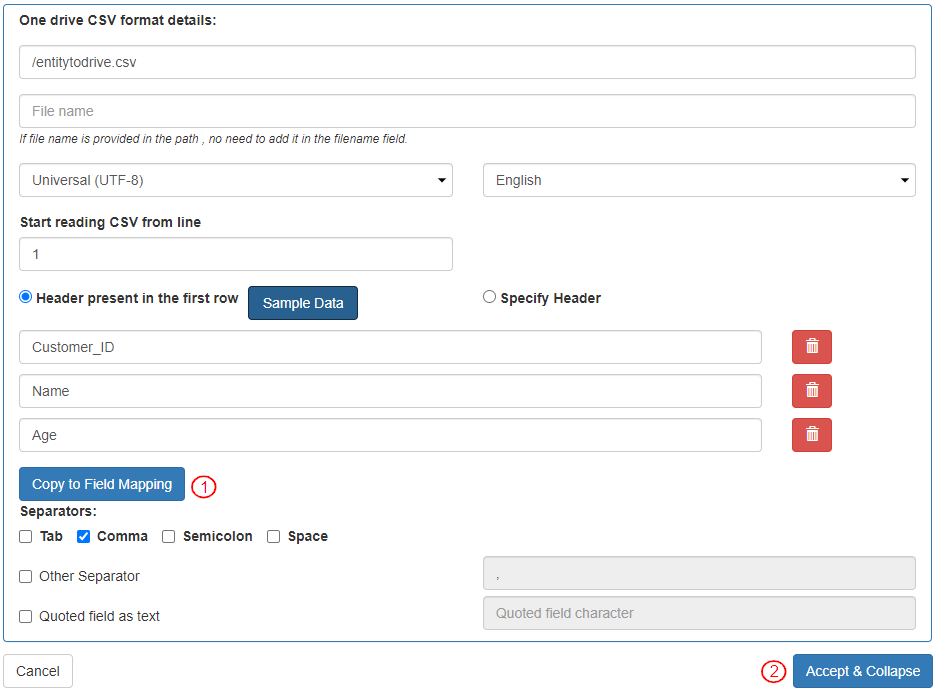
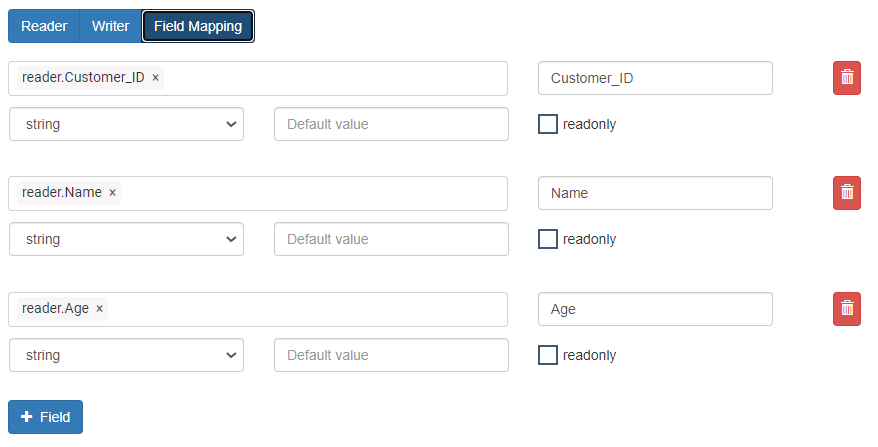
* Once the sample data is added, the writer fields are displayed:
* The column names are copied to Field Mapping by clicking “Copy to Field Mapping”.
* Click on "Accept & Collapse" to save the information.
* The “Writer” mode is “Append”.
* In the Field Mapping section, all the “Mapped Fields” are aligned.
* When the ETL pipeline is executed (after Save and Publish), the records will be added to the destination. The changes can be checked by downloading the file from OneDrive.
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.langstack.com/welcome/in-depth-learning/connectors/onedrive-connector/usage-of-onedrive-connector-in-etl-pipeline/onedrive-connector-as-a-destination.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.