> For the complete documentation index, see [llms.txt](https://docs.langstack.com/welcome/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.langstack.com/welcome/get-started/learn-langstack/introduction-to-etl-pipeline/etl-functions-execution-sequences-overview.md).
# ETL functions execution sequences overview
The "Code" tab contains functions where users can define actions for the ETL pipeline.
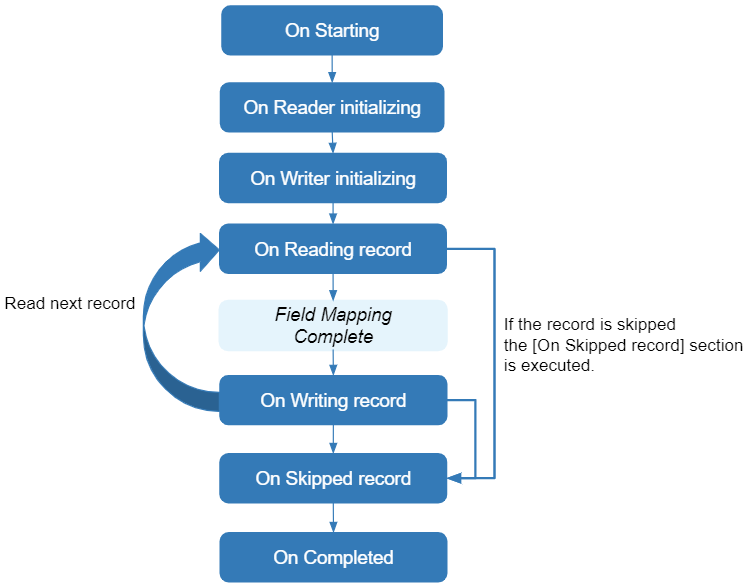
## Sequence of Functions
The ETL pipeline executes these functions in the "Code" tab in the following order:
## On Starting
When the ETL pipeline is run, the first function to be executed is the “On starting”. This function user can define the actions to be performed as soon as the ETL pipeline is initiated. On running the ETL pipeline, the relevant servers initiate all the services for the ETL pipeline and then perform the actions defined in this function as soon as the service is about to initialize the data source and data destination.
## On Reader initializing
After the “On Starting” function is processed, the “On Reader initializing” function is executed. The Reader is initialized, which finds and opens the relevant source to read the data from.
## On Writer initializing
The actions in the “On Writer initializing” function are executed once the Reader is initialized. The Writer is initialized, which finds and opens the relevant file or target entity to write the data.
## On Reading record
When the ETL pipeline Reader and Writer are initialized, the data is ready to be read from the source when the first record is read the “On Reading record” function is executed.
The “On Reading record” function can apply the actions to handle any adjustments to the data after it has been read from the source.
On clicking \[Show Shared Variables] in On Reading record>Action box>Variables, three variables are visible other than the StartupParameters variable: “reader,” “skippedReason,” and “skipRecord.” These variables are within the scope of the “On Reading record” function, and, therefore, available to all Action boxes within the “On Reading record” function.
* “reader” of the data type “Record”: This variable contains the details of the record as defined with the fields present in the Data Format tab>Reader>Source fields.
* “skippedReason” of the data type “string”: This variable contains the reason for skipping a record (if any) defined by the user.
* “skipRecord” is of data type “boolean”: This variable allows the user to skip the record and prevent writing it to the target destination by updating this variable to True. By default, it is set with False.
## Field Mapping completed
The field mapping defines the values read from the data source to where they need to be placed in the destination. Once the data is read from the data source, and the “On Reading record” function is executed, the relevant source fields are mapped to the fields in the destination. Once the data fields mapping is applied, the record is ready to be stored in the relevant destination.
## On Writing record
The “On Writing record” function is executed after the “On Reading record” function, and the field mapping is applied. In the “on Writing record” function, the record is ready to be written in the target entity. Users may define actions to update the field values of the mapped records. The values in the mapped records will be used when the record is written to the destination.
In the scope of “On Writing record” function three variables are visible and therefore are available to all Action boxes within this section. These are displayed by clicking \[Show Shared Variables] in On Writing record>Action box>Variables.
These variables are “mapped,” “skippedReason,” and “skipRecord.”
* “mapped” of the data type “Record”: This variable contains the details of the record as in the fields present in the Data Format tab>Field Mapping.
* “skippedReason” of the data type “string”: This variable contains the reason for skipping a record (if any) defined by the user.
* “skipRecord” of the data type “boolean”: This variable allows the user to skip the record and prevent writing it to the target destination by updating this variable to True, by default it is set to False.
## On Skipped record
The “On Skipped record” function defines the actions to be performed when records are skipped either in the “On Reading record” function or in the “On Writing record” function.
In the scope of this function two variables are visible and, therefore, are available to all Action boxes within the “On Skipped record” section. These are displayed by clicking \[Show Shared Variables] in On Skipped record>Action box>Variables.
These variables are “isFromReader,” “Skipped,” and “skippedReason”:
* “isFromReader”: This variable is of the data type “boolean”. Users can use this variable to verify if the record is skipped in the “on Reading record” section or “on Writing record” section.
* “Skipped”: This variable is of the data type “record” and contains the details of the skipped record.
* “skippedReason”: This variable is of the data type “string” and includes the reason for the skipped record.
Based on the function that contains the actions defining records to be skipped, the function execution sequence gets affected as follows:
1. If the actions for record skipping are defined in the “On Reading record” when the first record is read, the functions execution sequence is as follows:
1. The “On Reading record” function is executed.
2. The “On Skipped record” function is executed immediately after the “On Reading record”.
3. The “On Writing record” function is executed.
4. The “On Reading record” function is executed for the next record, and the cycle continues.
2. If skipping the record is set to True in the “On Writing record” when the record is read, the functon execution sequence is as follows:
1. The “On Reading record” function is executed.
2. The “On Writing record” function is executed.
3. The “On Skipped record” function is executed immediately after the “On Writing record”.
4. The “On Reading record” function is executed for the next record and the cycle continues.
## On Completed
The “On Completed” function consists of the actions to be performed when the service has completed i.e. when the last record of data has been processed and all the functions for the ETL pipeline have been executed.