# Reader
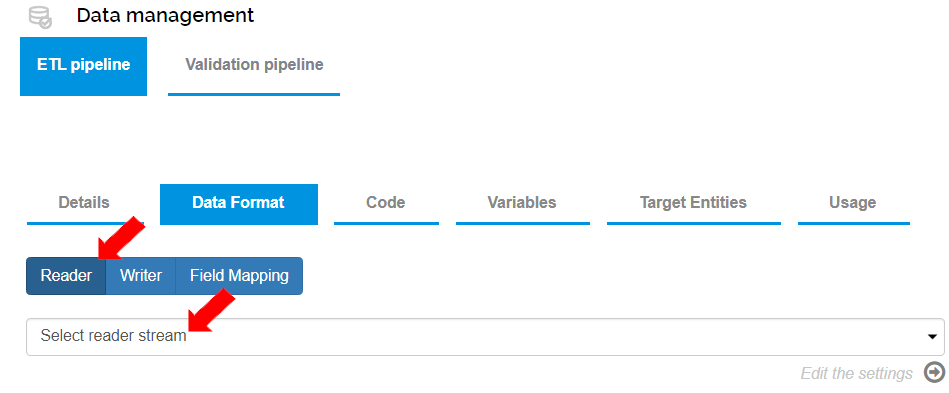
Records can be read from Langstack Entities or external data sources (using Connectors) through the settings defined in the ETL pipeline>Data Format>Reader tab.
## Data Source as a Connector
If the Data source is a connector:
* Based on the Connector type selected in the Details tab, users can define the reader stream as CSV Stream, Database Stream, JSON Stream, FixedWidth Stream, or Text Stream.
* When the steam is selected, and the relevant settings are defined, the reader fields are copied to the Source fields. Additional fields can be added by clicking the \[+ Field] button.
* The fields in this section are then aligned with destination fields using Field Mapping. The Reader fields can be all of the fields defined in the source or a few fields depending on the information required.
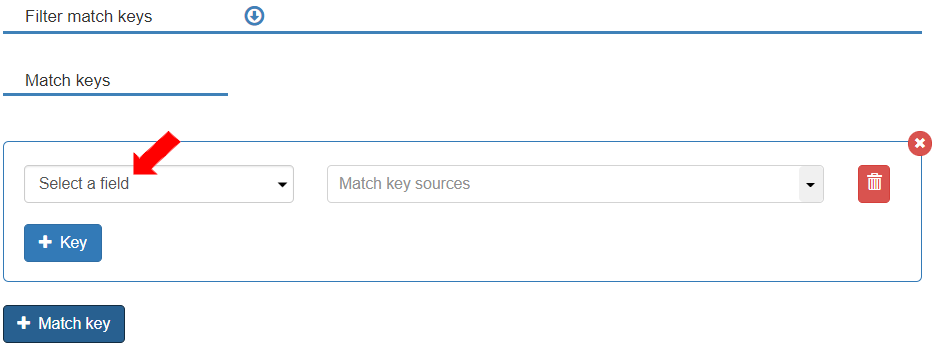
* Users can define match keys in the Filter Match key section. A match key can be added by clicking the \[+ Match key] button.
* The match key is then defined by selecting a field from the data source and the relevant source.
## Data Source as an Entity
If the Data source is an entity:
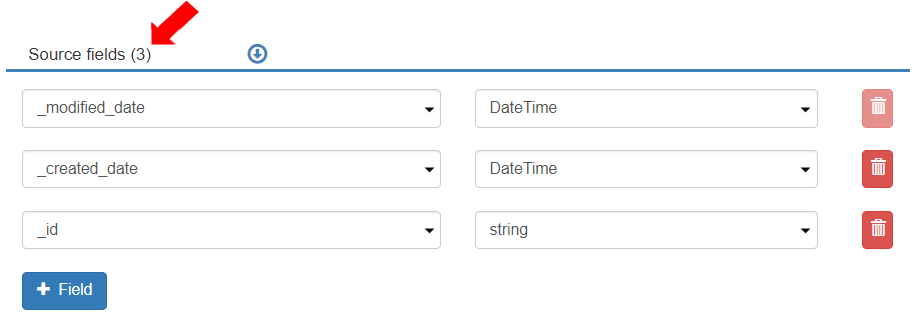
* The Reader tab displays the Source fields as the three columns of the Entity:\_modified\_date, \_created\_date, and \_id.
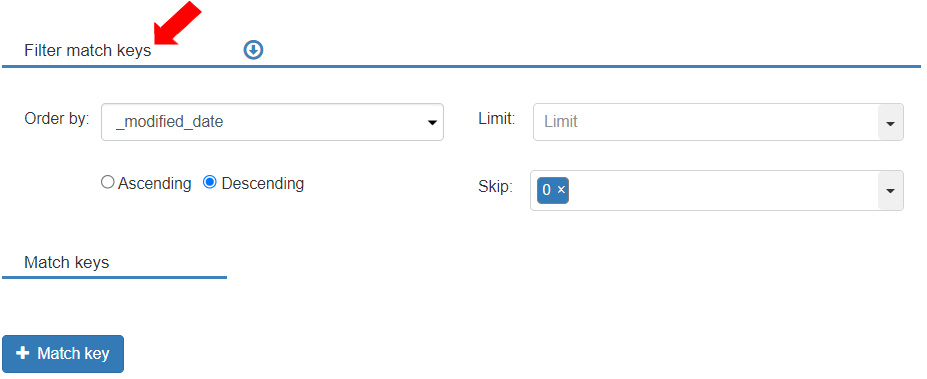
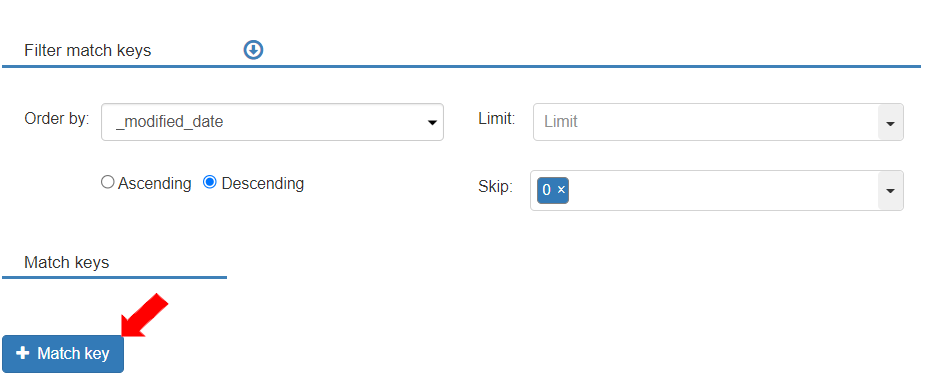
* The Filter Match key section is displayed with the following fields as per their execution sequence:
* Order By: Users can define ordering the records as ascending or descending for the match key.
* Skip: the number of records that are skipped before adding the records to the result.
* Limit: Users can define the limit for the number of records in the result. This number can be either a constant value or looked up from a variable or a function. If no value is specified, it means there is no limit on the number of records in the results.
* A match key can be added by clicking the \[+ Match key] button.
---
# Agent Instructions: Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter:
```
GET https://docs.langstack.com/welcome/get-started/learn-langstack/introduction-to-etl-pipeline/data-formats-in-etl-pipeline/reader.md?ask=
```
The question should be specific, self-contained, and written in natural language.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.